Deciding on the right technology?
The following technology choices are critical:
- Compute refers to the hosting model for the computing resources that your applications run on.
- Data stores include databases but also storage for message queues, caches, logs, and anything else that an application might persist to storage.
- Messaging technologies enable asynchronous messages between components of the system.
- SaaS Application functional capabilities – ERP, HR/HCM, CRM/CX, EPM, SCM solutions
- Integration technologies approach ( SOA ESB, API’s, Microservices, 3rd party middleware technologies)
You will probably have to make additional technology choices along the way, but these elements are central to most cloud applications and will determine many aspects of your design.
As an example of selecting a compute service: Microsoft Azure offers a number of ways to host your application code and the term compute refers to the hosting model for the computing resources that your application runs on. The following flowchart ascertain the right compute service for your application.
If your application consists of multiple workloads, evaluate each workload separately. A complete solution may incorporate two or more compute services.
Choose a candidate service
Use the following flowchart to select a candidate compute service.

Definitions:
- “Lift and shift” is a strategy for migrating a workload to the cloud without redesigning the application or making code changes. Also called rehosting.
- Cloud optimized is a strategy for migrating to the cloud by refactoring an application to take advantage of cloud-native features and capabilities.
The output from this flowchart is a starting point for consideration. Next, perform a more detailed evaluation of the service to see if it meets your needs.
Understand the basic features
- App Service. A managed service for hosting web apps, mobile app back ends, RESTful APIs, or automated business processes.
- Azure Kubernetes Service (AKS). A managed Kubernetes service for running containerized applications.
- Batch. A managed service for running large-scale parallel and high-performance computing (HPC) applications
- Container Instances. The fastest and simplest way to run a container in Azure, without having to provision any virtual machines and without having to adopt a higher-level service.
- Functions. A managed FaaS service.
- Service Fabric. A distributed systems platform that can run in many environments, including Azure or on premises.
- Virtual machines. Deploy and manage VMs inside an Azure virtual network.
Understand the hosting models
Cloud services, including Azure services, generally fall into three categories: IaaS, PaaS, or FaaS. (There is also SaaS, software-as-a-service, which is out of scope for this article.) It’s useful to understand the differences.
Infrastructure-as-a-Service (IaaS) lets you provision individual VMs along with the associated networking and storage components. Then you deploy whatever software and applications you want onto those VMs. This model is the closest to a traditional on-premises environment, except that Microsoft manages the infrastructure. You still manage the individual VMs.
Platform-as-a-Service (PaaS) provides a managed hosting environment, where you can deploy your application without needing to manage VMs or networking resources. Azure App Service is a PaaS service.
Functions-as-a-Service (FaaS) goes even further in removing the need to worry about the hosting environment. In a FaaS model, you simply deploy your code and the service automatically runs it. Azure Functions are a FaaS service.
There is a spectrum from IaaS to pure PaaS. For example, Azure VMs can autoscale by using virtual machine scale sets. This automatic scaling capability isn’t strictly PaaS, but it’s the type of management feature found in PaaS services.
In general, there is a tradeoff between control and ease of management. IaaS gives the most control, flexibility, and portability, but you have to provision, configure and manage the VMs and network components you create. FaaS services automatically manage nearly all aspects of running an application. PaaS services fall somewhere in between.
Consider limits and cost
Next, perform a more detailed evaluation, looking at the following aspects of the service:
- Service limits
- Cost
- SLA
- Regional availability
Based on this analysis, you may find that the initial candidate isn’t suitable for your particular application or workload. In that case, expand your analysis to include other compute services
The right data store?
Modern business systems manage increasingly large volumes of data. Data may be ingested from external services, generated by the system itself, or created by users. These data sets may have extremely varied characteristics and processing requirements. Businesses use data to assess trends, trigger business processes, audit their operations, analyze customer behavior, and many other things.
This heterogeneity means that a single data store is usually not the best approach. Instead, it’s often better to store different types of data in different data stores, each focused toward a specific workload or usage pattern. The term polyglot persistence is used to describe solutions that use a mix of data store technologies.
Selecting the right data store for your requirements is a key design decision. There are literally hundreds of implementations to choose from among SQL and NoSQL databases. Data stores are often categorized by how they structure data and the types of operations they support. This article describes several of the most common storage models. Note that a particular data store technology may support multiple storage models. For example, a relational database management systems (RDBMS) may also support key/value or graph storage. In fact, there is a general trend for so-called multi-model support, where a single database system supports several models. But it’s still useful to understand the different models at a high level.
Not all data stores in a given category provide the same feature-set. Most data stores provide server-side functionality to query and process data. Sometimes this functionality is built into the data storage engine. In other cases, the data storage and processing capabilities are separated, and there may be several options for processing and analysis. Data stores also support different programmatic and management interfaces.
Generally, you should start by considering which storage model is best suited for your requirements. Then consider a particular data store within that category, based on factors such as feature set, cost, and ease of management.
Relational database management systems
Relational databases organize data as a series of two-dimensional tables with rows and columns. Each table has its own columns, and every row in a table has the same set of columns. This model is mathematically based, and most vendors provide a dialect of the Structured Query Language (SQL) for retrieving and managing data. An RDBMS typically implements a transactionally consistent mechanism that conforms to the ACID (Atomic, Consistent, Isolated, Durable) model for updating information.
An RDBMS typically supports a schema-on-write model, where the data structure is defined ahead of time, and all read or write operations must use the schema. This is in contrast to most NoSQL data stores, particularly key/value types, where the schema-on-read model assumes that the client will be imposing its own interpretive schema on data coming out of the database, and is agnostic to the data format being written.
An RDBMS is very useful when strong consistency guarantees are important — where all changes are atomic, and transactions always leave the data in a consistent state. However, the underlying structures do not lend themselves to scaling out by distributing storage and processing across machines. Also, information stored in an RDBMS, must be put into a relational structure by following the normalization process. While this process is well understood, it can lead to inefficiencies, because of the need to disassemble logical entities into rows in separate tables, and then reassemble the data when running queries.
Relevant Azure services:
- Azure SQL Database
- Azure Database for MySQL
- Azure Database for PostgreSQL
- Azure Database for MariaDB
Key/value stores
A key/value store is essentially a large hash table. You associate each data value with a unique key, and the key/value store uses this key to store the data by using an appropriate hashing function. The hashing function is selected to provide an even distribution of hashed keys across the data storage.
Most key/value stores only support simple query, insert, and delete operations. To modify a value (either partially or completely), an application must overwrite the existing data for the entire value. In most implementations, reading or writing a single value is an atomic operation. If the value is large, writing may take some time.
An application can store arbitrary data as a set of values, although some key/value stores impose limits on the maximum size of values. The stored values are opaque to the storage system software. Any schema information must be provided and interpreted by the application. Essentially, values are blobs and the key/value store simply retrieves or stores the value by key.
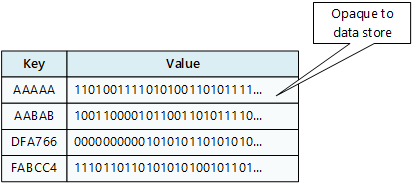
Key/value stores are highly optimized for applications performing simple lookups, but are less suitable for systems that need to query data across different key/value stores. Key/value stores are also not optimized for scenarios where querying by value is important, rather than performing lookups based only on keys. For example, with a relational database, you can find a record by using a WHERE clause, but key/values stores usually do not have this type of lookup capability for values.
A single key/value store can be extremely scalable, as the data store can easily distribute data across multiple nodes on separate machines.
Relevant Azure services:
- Cosmos DB
- Azure Cache for Redis
Document databases
A document database is conceptually similar to a key/value store, except that it stores a collection of named fields and data (known as documents), each of which could be simple scalar items or compound elements such as lists and child collections. The data in the fields of a document can be encoded in a variety of ways, including XML, YAML, JSON, BSON, or even stored as plain text. Unlike key/value stores, the fields in documents are exposed to the storage management system, enabling an application to query and filter data by using the values in these fields.
Typically, a document contains the entire data for an entity. What items constitute an entity are application specific. For example, an entity could contain the details of a customer, an order, or a combination of both. A single document may contain information that would be spread across several relational tables in an RDBMS.
A document store does not require that all documents have the same structure. This free-form approach provides a great deal of flexibility. Applications can store different data in documents as business requirements change.
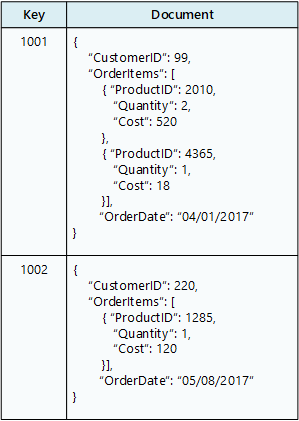
The application can retrieve documents by using the document key. This is a unique identifier for the document, which is often hashed, to help distribute data evenly. Some document databases create the document key automatically. Others enable you to specify an attribute of the document to use as the key. The application can also query documents based on the value of one or more fields. Some document databases support indexing to facilitate fast lookup of documents based on one or more indexed fields.
Many document databases support in-place updates, enabling an application to modify the values of specific fields in a document without rewriting the entire document. Read and write operations over multiple fields in a single document are usually atomic.
Relevant Azure service: Cosmos DB
Graph databases
A graph database stores two types of information, nodes and edges. You can think of nodes as entities. Edges which specify the relationships between nodes. Both nodes and edges can have properties that provide information about that node or edge, similar to columns in a table. Edges can also have a direction indicating the nature of the relationship.
The purpose of a graph database is to allow an application to efficiently perform queries that traverse the network of nodes and edges, and to analyze the relationships between entities. The following diagram shows an organization’s personnel database structured as a graph. The entities are employees and departments, and the edges indicate reporting relationships and the department in which employees work. In this graph, the arrows on the edges show the direction of the relationships.

This structure makes it straightforward to perform queries such as “Find all employees who report directly or indirectly to Sarah” or “Who works in the same department as John?” For large graphs with lots of entities and relationships, you can perform very complex analyses very quickly. Many graph databases provide a query language that you can use to traverse a network of relationships efficiently.
Relevant Azure service: Cosmos DB
Column-family databases
A column-family database organizes data into rows and columns. In its simplest form, a column-family database can appear very similar to a relational database, at least conceptually. The real power of a column-family database lies in its denormalized approach to structuring sparse data.
You can think of a column-family database as holding tabular data with rows and columns, but the columns are divided into groups known as column families. Each column family holds a set of columns that are logically related together and are typically retrieved or manipulated as a unit. Other data that is accessed separately can be stored in separate column families. Within a column family, new columns can be added dynamically, and rows can be sparse (that is, a row doesn’t need to have a value for every column).
The following diagram shows an example with two column families, Identity and Contact Info. The data for a single entity has the same row key in each column-family. This structure, where the rows for any given object in a column family can vary dynamically, is an important benefit of the column-family approach, making this form of data store highly suited for storing structured, volatile data.

Unlike a key/value store or a document database, most column-family databases store data in key order, rather than by computing a hash. Many implementations allow you to create indexes over specific columns in a column-family. Indexes let you retrieve data by columns value, rather than row key.
Read and write operations for a row are usually atomic with a single column-family, although some implementations provide atomicity across the entire row, spanning multiple column-families.
Relevant Azure service: HBase in HDInsight
Data analytics
Data analytics stores provide massively parallel solutions for ingesting, storing, and analyzing data. This data is distributed across multiple servers using a share-nothing architecture to maximize scalability and minimize dependencies. The data is unlikely to be static, so these stores must be able to handle large quantities of information, arriving in a variety of formats from multiple streams, while continuing to process new queries.
Relevant Azure services:
- Azure Synapse Analytics
- Azure Data Lake
- Azure Data Explorer
Search Engine Databases
A search engine database supports the ability to search for information held in external data stores and services. A search engine database can be used to index massive volumes of data and provide near real-time access to these indexes. Although search engine databases are commonly thought of as being synonymous with the web, many large-scale systems use them to provide structured and ad-hoc search capabilities on top of their own databases.
The key characteristics of a search engine database are the ability to store and index information very quickly, and provide fast response times for search requests. Indexes can be multi-dimensional and may support free-text searches across large volumes of text data. Indexing can be performed using a pull model, triggered by the search engine database, or using a push model, initiated by external application code.
Searching can be exact or fuzzy. A fuzzy search finds documents that match a set of terms and calculates how closely they match. Some search engines also support linguistic analysis that can return matches based on synonyms, genre expansions (for example, matching dogs to pets), and stemming (matching words with the same root).
Relevant Azure service: Azure Search
Time Series Databases
Time series data is a set of values organized by time, and a time series database is a database that is optimized for this type of data. Time series databases must support a very high number of writes, as they typically collect large amounts of data in real time from a large number of sources. Updates are rare, and deletes are often done as bulk operations. Although the records written to a time-series database are generally small, there are often a large number of records, and total data size can grow rapidly.
Time series databases are good for storing telemetry data. Scenarios include IoT sensors or application/system counters.
Relevant Azure service: Time Series Insights
Object storage
Object storage is optimized for storing and retrieving large binary objects (images, files, video and audio streams, large application data objects and documents, virtual machine disk images). Objects in these store types are composed of the stored data, some metadata, and a unique ID for accessing the object. Object stores enables the management of extremely large amounts of unstructured data.
Relevant Azure service: Blob Storage
Shared files
Sometimes, using simple flat files can be the most effective means of storing and retrieving information. Using file shares enables files to be accessed across a network. Given appropriate security and concurrent access control mechanisms, sharing data in this way can enable distributed services to provide highly scalable data access for performing basic, low-level operations such as simple read and write requests.
What are the different types of messages and the entities that participate in a messaging infrastructure.
This articles discussed Azure messaging services. The options include Azure Service Bus, Event Grid, and Event Hubs.
At an architectural level, a message is a datagram created by an entity (producer), to distribute information so that other entities (consumers) can be aware and act accordingly. The producer and the consumer can communicate directly or optionally through an intermediary entity (message broker). This article focuses on asynchronous messaging using a message broker.
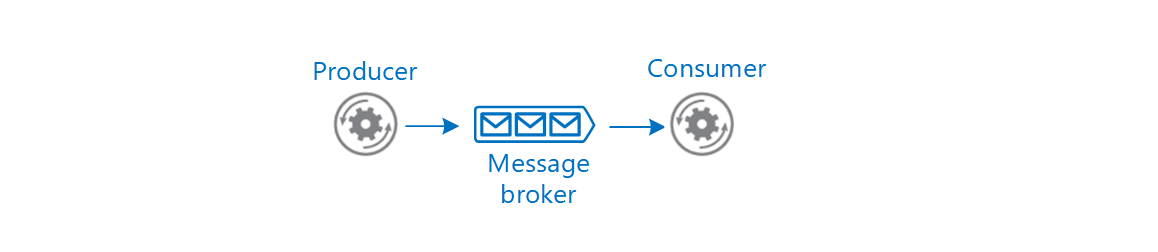
Messages can be classified into two main categories. If the producer expects an action from the consumer, that message is a command. If the message informs the consumer that an action has taken place, then the message is an event.
Commands
The producer sends a command with the intent that the consumer(s) will perform an operation within the scope of a business transaction.
A command is a high-value message and must be delivered at least once. If a command is lost, the entire business transaction might fail. Also, a command shouldn’t be processed more than once. Doing so might cause an erroneous transaction. A customer might get duplicate orders or billed twice.
Commands are often used to manage the workflow of a multistep business transaction. Depending on the business logic, the producer may expect the consumer to acknowledge the message and report the results of the operation. Based on that result, the producer may choose an appropriate course of action.
Events
An event is a type of message that a producer raises to announce facts.
The producer (known as the publisher in this context) has no expectations that the events will result in any action.
Interested consumer(s), can subscribe, listen for events, and take actions depending on their consumption scenario. Events can have multiple subscribers or no subscribers at all. Two different subscribers can react to an event with different actions and not be aware of one another.
The producer and consumer are loosely coupled and managed independently. The consumer isn’t expected to acknowledge the event back to the producer. A consumer that is no longer interested in the events, can unsubscribe. The consumer is removed from the pipeline without affecting the producer or the overall functionality of the system.
There are two categories of events:
- The producer raises events to announce discrete facts. A common use case is event notification. For example, Azure Resource Manager raises events when it creates, modifies, or deletes resources. A subscriber of those events could be a Logic App that sends alert emails.
- The producer raises related events in a sequence, or a stream of events, over a period of time. Typically, a stream is consumed for statistical evaluation. The evaluation can be done within a temporal window or as events arrive. Telemetry is a common use case, for example, health and load monitoring of a system. Another case is event streaming from IoT devices.
A common pattern for implementing event messaging is the Publisher-Subscriber pattern.
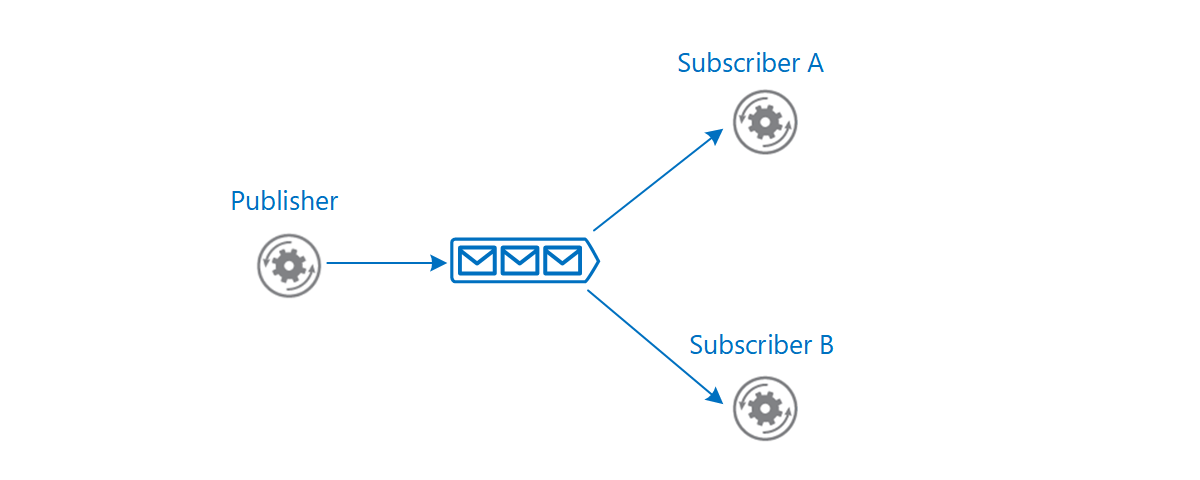
Role and benefits of a message broker
An intermediate message broker provides the functionality of moving messages from producer to consumer and can offer additional benefits.
Decoupling
A message broker decouples the producer from the consumer in the logic that generates and uses the messages, respectively. In a complex workflow, the broker can encourage business operations to be decoupled and help coordinate the workflow.
For example, a single business transaction requires distinct operations that are performed in a business logic sequence. The producer issues a command that signals a consumer to start an operation. The consumer acknowledges the message in a separate queue reserved for lining up responses for the producer. Only after receiving the response, the producer sends a new message to start the next operation in the sequence. A different consumer processes that message and sends a completion message to the response queue. By using messaging, the services coordinate the workflow of the transaction among themselves.
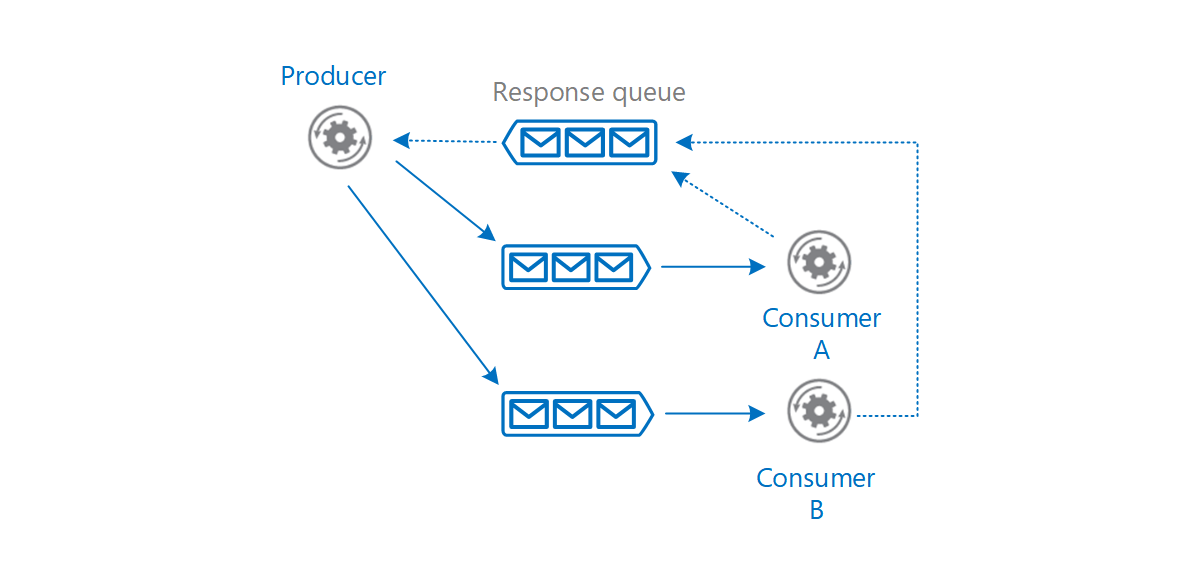
A message broker provides temporal decoupling. The producer and consumer don’t have to run concurrently. A producer can send a message to the message broker regardless of the availability of the consumer. Conversely, the consumer isn’t restricted by the producer’s availability.
For example, the user interface of a web app generates messages and uses a queue as the message broker. When ready, consumers can retrieve messages from the queue and perform the work. Temporal decoupling helps the user interface to remain responsive. It’s not blocked while the messages are handled asynchronously.
Certain operations can take long to complete. After issuing a command, the producer shouldn’t have to wait until the consumer completes it. A message broker helps asynchronous processing of messages.
Load balancing
Producers may post a large number of messages that are serviced by many consumers. Use a message broker to distribute processing across servers and improve throughput. Consumers can run on different servers to spread the load. Consumers can be added dynamically to scale out the system when needed or removed otherwise.
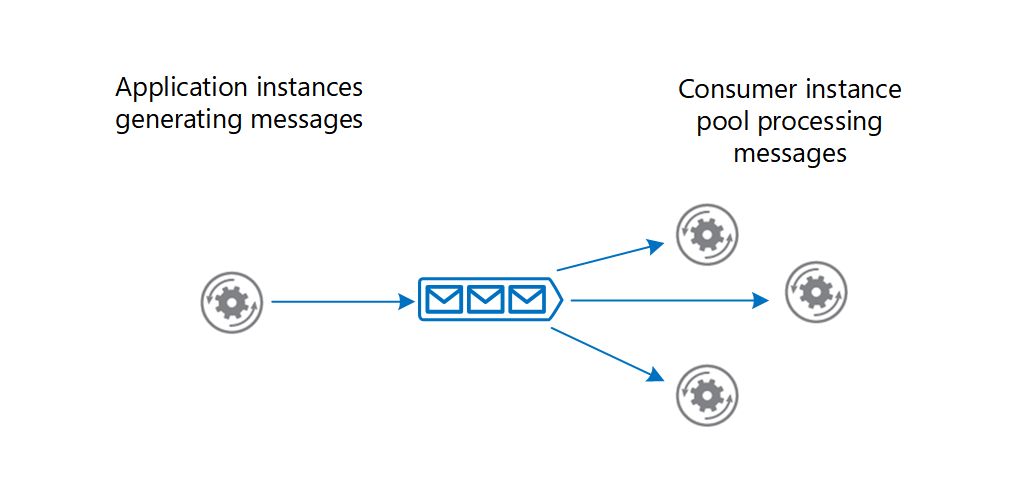
The Competing Consumers Pattern explains how to process multiple messages concurrently to optimize throughput, to improve scalability and availability, and to balance the workload.
Load leveling
The volume of messages generated by the producer or a group of producers can be variable. At times there might be a large volume causing spikes in messages. Instead of adding consumers to handle this work, a message broker can act as a buffer, and consumers gradually drain messages at their own pace without stressing the system.
The Queue-based Load Leveling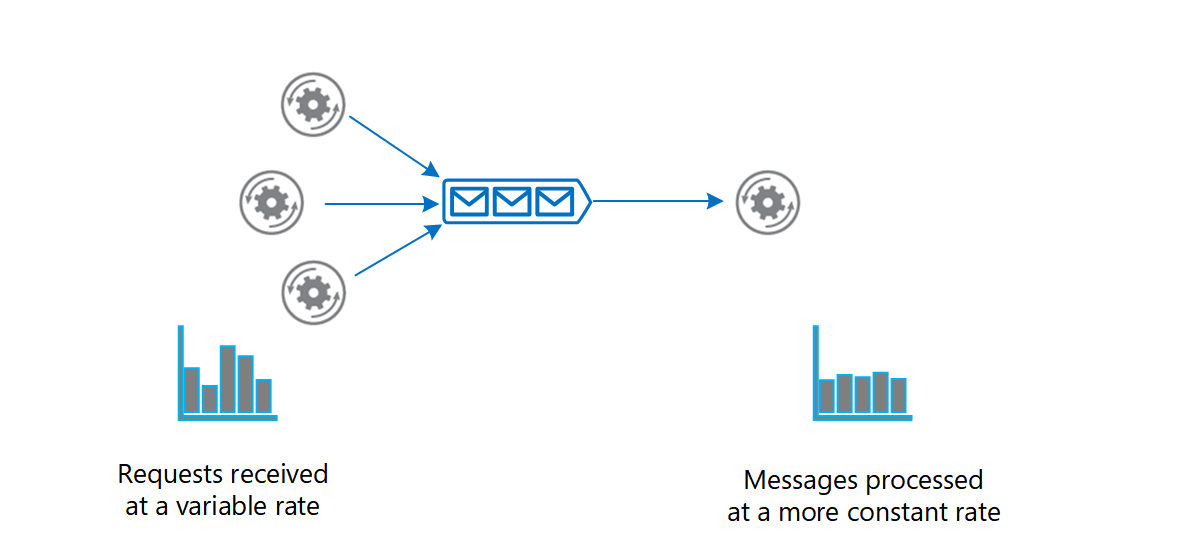
Reliable messaging
A message broker helps ensure that messages aren’t lost even if communication fails between the producer and consumer. The producer can post messages to the message broker and the consumer can retrieve them when communication is reestablished. The producer isn’t blocked unless it loses connectivity with the message broker.
Resilient messaging
A message broker can add resiliency to the consumers in your system. If a consumer fails while processing a message, another instance of the consumer can process that message. The reprocessing is possible because the message persists in the broker.
Technology choices for a message broker
Azure provides several message broker services, each with a range of features. Before choosing a service, determine the intent and requirements of the message.
Azure Service Bus
Azure Service Bus queues are well suited for transferring commands from producers to consumers. Here are some considerations.
Pull model
A consumer of a Service Bus queue constantly polls Service Bus to check if new messages are available. The client SDKs and Azure Functions trigger for Service Bus abstract that model. When a new message is available, the consumer’s callback is invoked, and the message is sent to the consumer.
Guaranteed delivery
Service Bus allows a consumer to peek the queue and lock a message from other consumers.
It’s the responsibility of the consumer to report the processing status of the message. Only when the consumer marks the message as consumed, Service Bus removes the message from the queue. If a failure, timeout, or crash occurs, Service Bus unlocks the message so that other consumers can retrieve it. This way messages aren’t lost in transfer.
A producer might accidentally send the same message twice. For instance, a producer instance fails after sending a message. Another producer replaces the original instance and sends the message again. Azure Service Bus queues provide a built-in de-duping capability that detects and removes duplicate messages. There’s still a chance that a message is delivered twice. For example, if a consumer fails while processing, the message is returned to the queue and is retrieved by the same or another consumer. The message processing logic in the consumer should be idempotent so that even if the work is repeated, the state of the system isn’t changed. For more information about idempotency, see Idempotency Patterns on Jonathon Oliver’s blog.
Message ordering
If you want consumers to get the messages in the order they are sent, Service Bus queues guarantee first-in-first-out (FIFO) ordered delivery by using sessions. A session can have one or more messages. The messages are correlated with the SessionId property. Messages that are part of a session, never expire. A session can be locked to a consumer to prevent its messages from being handled by a different consumer.
For more information, see Message Sessions.
Message persistence
Service bus queues support temporal decoupling. Even when a consumer isn’t available or unable to process the message, it remains in the queue.
Checkpoint long-running transactions
Business transactions can run for a long time. Each operation in the transaction can have multiple messages. Use checkpointing to coordinate the workflow and provide resiliency in case a transaction fails.
Service Bus queues allow checkpointing through the session state capability. State information is incrementally recorded in the queue (SetState) for messages that belong to a session. For example, a consumer can track progress by checking the state (GetState) every now and then. If a consumer fails, another consumer can use state information to determine the last known checkpoint to resume the session.
Dead-letter queue (DLQ)
A Service Bus queue has a default subqueue, called the dead-letter queue (DLQ) to hold messages that couldn’t be delivered or processed. Service Bus or the message processing logic in the consumer can add messages to the DLQ. The DLQ keeps the messages until they are retrieved from the queue.
Here are examples when a message can end up being in the DLQ:
- A poison message is a message that cannot be handled because it’s malformed or contains unexpected information. In Service Bus queues, you can detect poison messages by setting the MaxDeliveryCount property of the queue. If number of times the same message is received exceeds that property value, Service Bus moves the message to the DLQ.
- A message might no longer be relevant if it isn’t processed within a period. Service Bus queues allow the producer to post messages with a time-to-live attribute. If this period expires before the message is received, the message is placed in the DLQ.
Examine messages in the DLQ to determine the reason for failure.
Hybrid solution
Service Bus bridges on-premises systems and cloud solutions. On-premises systems are often difficult to reach because of firewall restrictions. Both the producer and consumer (either can be on-premises or the cloud) can use the Service Bus queue endpoint as the pickup and drop off location for messages.
Topics and subscriptions
Service Bus supports the Publisher-Subscriber pattern through Service Bus topics and subscriptions.
This feature provides a way for the producer to broadcast messages to multiple consumers. When a topic receives a message, it’s forwarded to all the subscribed consumers. Optionally, a subscription can have filter criteria that allows the consumer to get a subset of messages. Each consumer retrieves messages from a subscription in a similar way to a queue.
For more information, see Azure Service Bus topics.
Azure Event Grid
Azure Event Grid is recommended for discrete events. Event Grid follows the Publisher-Subscriber pattern. When event sources trigger events, they are published to Event grid topics. Consumers of those events create Event Grid subscriptions by specifying event types and event handler that will process the events. If there are no subscribers, the events are discarded. Each event can have multiple subscriptions.
Push Model
Event Grid propagates messages to the subscribers in a push model. Suppose you have an event grid subscription with a webhook. When a new event arrives, Event Grid posts the event to the webhook endpoint.
Integrated with Azure
Choose Event Grid if you want to get notifications about Azure resources. Many Azure services act as event sources that have built-in Event Grid topics. Event Grid also supports various Azure services that can be configured as event handlers. It’s easy to subscribe to those topics to route events to event handlers of your choice. For example, you can use Event Grid to invoke an Azure Function when a blob storage is created or deleted.
Custom topics
Create custom Event Grid topics, if you want to send events from your application or an Azure service that isn’t integrated with Event Grid.
For example, to see the progress of an entire business transaction, you want the participating services to raise events as they are processing their individual business operations. A web app shows those events. One way is to create a custom topic and add a subscription with your web app registered through an HTTP WebHook. As business services send events to the custom topic, Event Grid pushes them to your web app.
Filtered events
You can specify filters in a subscription to instruct Event Grid to route only a subset of events to a specific event handler. The filters are specified in the subscription schema. Any event sent to the topic with values that match the filter are automatically forwarded to that subscription.
For example, content in various formats are uploaded to Blob Storage. Each time a file is added, an event is raised and published to Event Grid. The event subscription might have a filter that only sends events for images so that an event handler can generate thumbnails.
For more information about filtering, see Filter events for Event Grid.
High throughput
Event Grid can route 10,000,000 events per second per region. The first 100,000 operations per month are free. For cost considerations, see How much does Event Grid cost?
Resilient delivery
Even though successful delivery for events isn’t as crucial as commands, you might still want some guarantee depending on the type of event. Event Grid offers features that you can enable and customize, such as retry policies, expiration time, and dead lettering. For more information, see Delivery and retry.
Event Grid’s retry process can help resiliency but it’s not fail-safe. In the retry process, Event Grid might deliver the message more than once, skip, or delay some retries if the endpoint is unresponsive for a long time. For more information, see Retry schedule and duration.
You can persist undelivered events to a blob storage account by enabling dead-lettering. There’s a delay in delivering the message to the blob storage endpoint and if that endpoint is unresponsive, then Event Grid discards the event. For more information, see Dead letter and retry policies.
Azure Event Hubs
When working with an event stream, Azure Event Hubs is the recommended message broker. Essentially, it’s a large buffer that’s capable of receiving large volumes of data with low latency. The received data can be read quickly through concurrent operations. You can transform the received data by using any real-time analytics provider. Event Hubs also provides the capability to store events in a storage account.
Fast ingestion
Event Hubs is capable of ingesting millions of events per second. The events are only appended to the stream and are ordered by time.
Pull model
Like Event Grid, Event Hubs also offers Publisher-Subscriber capabilities. A key difference between Event Grid and Event Hubs is in the way event data is made available to the subscribers. Event Grid pushes the ingested data to the subscribers whereas Event Hub makes the data available in a pull model. As events are received, Event Hubs appends them to the stream. A subscriber manages its cursor and can move forward and back in the stream, select a time offset, and replay a sequence at its pace.
Stream processors are subscribers that pull data from Event Hubs for the purposes of transformation and statistical analysis. Use Azure Stream Analytics and Apache Spark for complex processing such as aggregation over time windows or anomaly detection.
If you want to act on each event per partition, you can pull the data by using Event Processing Host or by using built in connector such as Logic Apps to provide the transformation logic. Another option is to use Azure Functions.
Partitioning
A partition is a portion of the event stream. The events are divided by using a partition key. For example, several IoT devices send device data to an event hub. The partition key is the device identifier. As events are ingested, Event Hubs moves them to separate partitions. Within each partition, all events are ordered by time.
A consumer is an instance of code that processes the event data. Event Hubs follows a partitioned consumer pattern. Each consumer only reads a specific partition. Having multiple partitions results in faster processing because the stream can be read concurrently by multiple consumers.
Instances of the same consumer make up a single consumer group. Multiple consumer groups can read the same stream with different intentions. Suppose an event stream has data from a temperature sensor. One consumer group can read the stream to detect anomalies such as a spike in temperature. Another can read the same stream to calculate a rolling average temperature in a temporal window.
Event Hubs supports the Publisher-Subscriber pattern by allowing multiple consumer groups. Each consumer group is a subscriber.
For more information about Event Hub partitioning, see Partitions.
Event Hubs Capture
The Capture feature allows you to store the event stream to an Azure Blob storage or Data Lake Storage. This way of storing events is reliable because even if the storage account isn’t available, Capture keeps your data for a period, and then writes to the storage after it’s available.
Storage services can also offer additional features for analyzing events. For example, by taking advantage of the access tiers of a blob storage account, you can store events in a hot tier for data that needs frequent access. You might use that data for visualization. Alternately, you can store data in the archive tier and retrieve it occasionally for auditing purposes.
Capture stores all events ingested by Event Hubs and is useful for batch processing. You can generate reports on the data by using a MapReduce function. Captured data can also serve as the source of truth. If certain facts were missed while aggregating the data, you can refer to the captured data.